GOOGLE EARTH ENGINE FOR ECOLOGY AND CONSERVATION
Practical 8: Continuous change detection & classification
by Joseph White
Learning Objectives
By the end of this practical you should be able to:
- Understand the value of continuity in change detection
- Understand and implement continuous change detection
- Classify a region using bands and regression variables
- Obtain ‘regular’ image and change information
Access the slides here: shorturl.at/elvTW
Introduction
For many land cover change analyses, particularly in forest detection, we have previously relied on annual (or longer interval) land classifications. This includes datasets such as Hansen Global Forest Change or Global Forest Cover Change. These data are immensely valuable and do a good job at compensating for difficulties in monitoring forests in regions with lots of clouds. However, there are limitations to understanding land cover change, when we only have a few observation epochs. This is where Continuous Change Detection and Classification comes in. Using all available satellite observations, the CCDC algorithm provides a more comprehensive approach to classifying images and detecting change. This practical gives an overview of this within the context of a critically endangered Mediterranean-type Ecosystem in southwestern South Africa, known as Renosterveld.
Some useful resources to better understand the CCDC approach and implementation in GEE can be found below:
- Souza Jr. et al 2005
- Zhu & Woodcock 2014
- Arévalo et al. 2020
- Documentation for CCDC in GEE
- CCDC in GEE Apps
The analysis is broken into two parts. Part 1 addresses applying a classification to any time point in your ImageCollection. Part 2 addresses exporting variables for further analysis. Part 1 relies on two external libraries and shows aspects of the required workflow. I recommend trying the full workflow that relies on the excellent CCDC utilities package alone when running CCDC with your own data (Documentation for CCDC in GEE).
Part 1: Access the completed practical script here.
The end product for Part 1:
Set up your workspace. Start by creating your study region polygon.
///////////////////////////////// ///// Select your study region // ///////////////////////////////// // Create a polygon/import a featureCollection ///////////////////////////////// ///// Set map options /////////// ///////////////////////////////// var renost_all = ee.FeatureCollection('users/jdmwhite/renosterveld_veg_types') var studyRegion = renost_all.filter(ee.Filter.eq('NAME','Central Rens Shale Renosterveld')) Map.centerObject(studyRegion, 10) Map.addLayer(studyRegion, {}, 'studyRegion', false) ///////////////////////////////// ///// Load extra libraries ////// ///////////////////////////////// // The utilities package for ccdc is the best developed of the ccdc api's var utils = require('users/parevalo_bu/gee-ccdc-tools:ccdcUtilities/api') // the temporal segmentation package does a good job doing some basic ccdc functions var temporalSegmentation = require('users/wiell/temporalSegmentation:temporalSegmentation'); // the palettes package for map outputs var palettes = require('users/gena/packages:palettes');
Next set up the required parameters for the CCDC analysis and load in the Landsat collection. Plot out the least cloudy image from the Landsat collection, which you can use to create your training data with the point tool.
///////////////////////////////// ///// Set up parameters ///////// ///////////////////////////////// // Parameters for change detection algorithm var changeDetection = { breakpointBands: ['GREEN','RED','NIR','SWIR1','SWIR2','NDVI'], // bands to use for regression tmaskBands: ['GREEN','SWIR2'], lambda: 20/10000, // tuning parameter // minObservations: 6, // observation window // chiSquareProbability: .99, // threshold for change detection // minNumOfYearsScaler: 1.33, // min number of years to apply new fitting dateFormat: 0, // 0 is for Julian days; 2 is Unix (ms since 1970) // // 0 works for segments; 2 works for raw CCD results (i.e Part 2) // maxIterations: 25000 // number of runs for LASSO regression convergence } // Overall parameters var params = { start: '1993-01-01', end: '2003-01-01', ChangeDetection: changeDetection, StudyRegion: studyRegion } /////////////////////////////////////////// ///// Import & Pre-Process Landsat Data /// /////////////////////////////////////////// // Filter by date and a location in South Africa var filteredLandsat = utils.Inputs.getLandsat() // using the utility package loaded earlier .filterBounds(params.StudyRegion) .map(function(image) {return image.clip(studyRegion)}) .filterDate(params.start, params.end) .select(['BLUE','GREEN','RED','NIR','SWIR1','SWIR2','NDVI']) print('Collection size:', filteredLandsat.size()) // print('Collection:', filteredLandsat) // Investigate landsat data // Add the image with the least cloud to the map Map.addLayer(filteredLandsat.sort('CLOUD_COVER').first(), {bands: ['RED', 'GREEN', 'BLUE'] ,min: 0, max: 0.15}, 'Least cloudy image RGB', false); Map.addLayer(filteredLandsat.sort('CLOUD_COVER').first(), {bands: ['NIR', 'RED', 'GREEN'] ,min: 0, max: 0.6}, 'Least cloudy image FCC', false); // Save the date of the image, which we use for creating a training data set var img_date = ee.Date(filteredLandsat.sort('CLOUD_COVER').first().get('system:time_start')).format("yyyy-MM-dd").aside(print, 'Date cloud free image'); // At this point you can create your training data // Use the point tool to create classes of data based on the cloudless image // Add our landsat dataset to the params dictionary params.ChangeDetection['collection'] = filteredLandsat print('Parameters:', params);
Now that we have defined our parameters, loaded in and pre-processed the landsat imagery, the CCDC alogrithm can be easily run. Using the temporalSegmentation package, you can chart out the CCDC segments for a specified point (i.e. pixel) and observe the break points detected.
/////////////////////////////////////////// ///// Run CCDC Algorithm ////////////////// /////////////////////////////////////////// var results = ee.Algorithms.TemporalSegmentation.Ccdc(params.ChangeDetection) print('CCDC results:',results.bandNames()); // Add the harmonic regression segments to the chart // Drop a point within your study region to display the chart temporalSegmentation.chartPoint({ image: results, point: change_point_3, bandName: 'NDVI', collection: filteredLandsat, callback: function (chart) { print(chart .setOptions({ title: 'Landsat: Change Point 1', vAxis: {title: 'NDVI', maxValue: 1, minValue: 0}, hAxis: {title: 'Date'}, pointSize: 0, lineWidth: 1.5, series: {0: {pointSize: 1, lineWidth: 0}} }) ) } })

In this chart, the CCDC algorithm suggests there was a change in land cover around late 2000. The y-axis shows changes in NDVI.
At this point, it is a good idea to save the CCDC output to your asset. This will help further down the line, by saving memory and will make your code run a lot more smoothly. Once export, you can comment out this code and load the image back in from your assets.
/////////////////////////////////////////////////////// /// Only run this bit once & save results to ASSETS /// /////////////////////////////////////////////////////// var segments = temporalSegmentation.Segments(results) // Create temporal segments // This is the image you will use for the rest of Part 1 // // Export as asset. Include same options as for regular exports. // // Skip the image and pyramidingPolicy though, which gets defaulted. // segments.toAsset({ // description: 'renost_ccdc_segments_1993_2003_0_v1', // region: studyRegion, // scale: 30, // crs: 'EPSG:4326' // }) // // This is the image you will use for Part 2 // Export.image.toAsset({ // image: results, // scale: 30, // description: 'renost_ccdc_raw_1993_2003_2_v1', // maxPixels: 1e13, // region: studyRegion, // pyramidingPolicy: { // '.default': 'sample' // } // }) // Load the CCDC results back in var segmentsImage = ee.Image('users/jdmwhite/renost_ccdc_segments_1993_2003_0_v1') // Load CCDC asset var segments = temporalSegmentation.Segments(segmentsImage) // Create temporal segments
Once the CCDC image is loaded back in, we can now prepare the training and testing points for classification. The training points require a land cover type label and a date, which corresponds to the image the data was collected from.
/////////////////////////////////////////////////////// /// Prepare data for classification /////////////////// /////////////////////////////////////////////////////// // Prepare the training point data // Convert the ee.Geometry.Multipoint to FeatureCollections and set type & date values // Renosterveld var Renost = ee.FeatureCollection(renost.coordinates().map(function(p) { var type = ee.Feature(ee.Geometry.Point(p), {type: 1}) // 1 for Renosterveld var date_type = type.set('date', img_date) return date_type})) // Agriculture var Agri = ee.FeatureCollection(agri.coordinates().map(function(p) { var type = ee.Feature(ee.Geometry.Point(p), {type: 0}) // 0 for Agriculture var date_type = type.set('date', img_date) return date_type})) //Stratified random sampling for each class // First for Renosterveld var Renost_table = Renost.randomColumn({seed: 16}); var Renost_training = Renost_table.filter(ee.Filter.lt('random', 0.80)); var Renost_test = Renost_table.filter(ee.Filter.gte('random', 0.80)); // Next for Agriculture var Agri_table = Agri.randomColumn({seed: 16}); var Agri_training = Agri_table.filter(ee.Filter.lt('random', 0.80)); var Agri_test = Agri_table.filter(ee.Filter.gte('random', 0.80)); //Combine our Renosterveld & Agriculture reference points for our training & test data var trainingPoints = Renost_training.merge(Agri_training); var testingPoints = Renost_test.merge(Agri_test)//.aside(print, 'test data'); // Function to remove the random column, as it isn't needed for later var removeProperty = function(feat, property) { var properties = feat.propertyNames() var selectProperties = properties.filter(ee.Filter.neq('item', property)) return feat.select(selectProperties) } // remove the random property in each feature var trainingPoints = trainingPoints.map(function(feat) { return removeProperty(feat, 'random') }) print(trainingPoints.first(), 'training points') var testingPoints = testingPoints.map(function(feat) { return removeProperty(feat, 'random') })
We now want to sampe the pixels for each point in the training and testing data. First use the mapSegment function to extract information for each temporal segment. Then select the images (by date) that you wish to classify. Lastly, sample the data for both training and testing datasets.
// Function to extract an image from a segment. Used when sampling and classifying. // Provide whatever information you think helps the classification in this image var mapSegment = function(segment) { var image = segment.toImage() var rmse = image.select(['.*_rmse']) var ndviCoefs = segment.coefs('NDVI') var fit = segment.slice() return ee.Image([fit, rmse, ndviCoefs]) } // Create regression for two dates to provide quick feedback on classification results var Segment_1994 = segments.findByDate('1994-01-01', 'closest') // selects image closest to this date var Image_1994 = mapSegment(Segment_1994) var Segment_2003 = segments.findByDate('2002-01-01', 'closest') // selects image closest to this date var Image_2003 = mapSegment(Segment_2003) print('test image bands:', Image_2003.bandNames()); // create the training data by overlaying the ref data on the segments var trainingData = segments.sample(trainingPoints, mapSegment, 30) // select scale print('trainingData:', trainingData.first()) // create the training data by overlaying the ref data on the segments var testingData = segments.sample(testingPoints, mapSegment, 30) // select scale print('testingData:', testingData.first())
Now we can train our classifier using a Random Forest. Once the classifier is trained, classify both extracted images. Next you can run the model evaluation.
/////////////////////////////////////////////////////// /// Classify a single image /////////////////////////// /////////////////////////////////////////////////////// var classifier = ee.Classifier.smileRandomForest(50) .train({ features: trainingData, classProperty: 'type' }); var Classification_1994 = Image_1994 .classify(classifier.setOutputMode('CLASSIFICATION')) // print(Classification_1994.first(), 'Classification 1994'); var testClassification_2003 = Image_2003 .classify(classifier.setOutputMode('CLASSIFICATION')) // print(Classification_2003.first(), 'Classification 2003'); /////////////////////////////////////////////////////// /// Model Evaluation ////////////////////////////////// /////////////////////////////////////////////////////// //Test accuracy var testClassification = testingData.classify(classifier); print('ConfusionMatrix', testClassification.errorMatrix('type', 'classification')); print('TestAccuracy', testClassification.errorMatrix('type', 'classification').accuracy()); print('Important variables', classifier.explain())
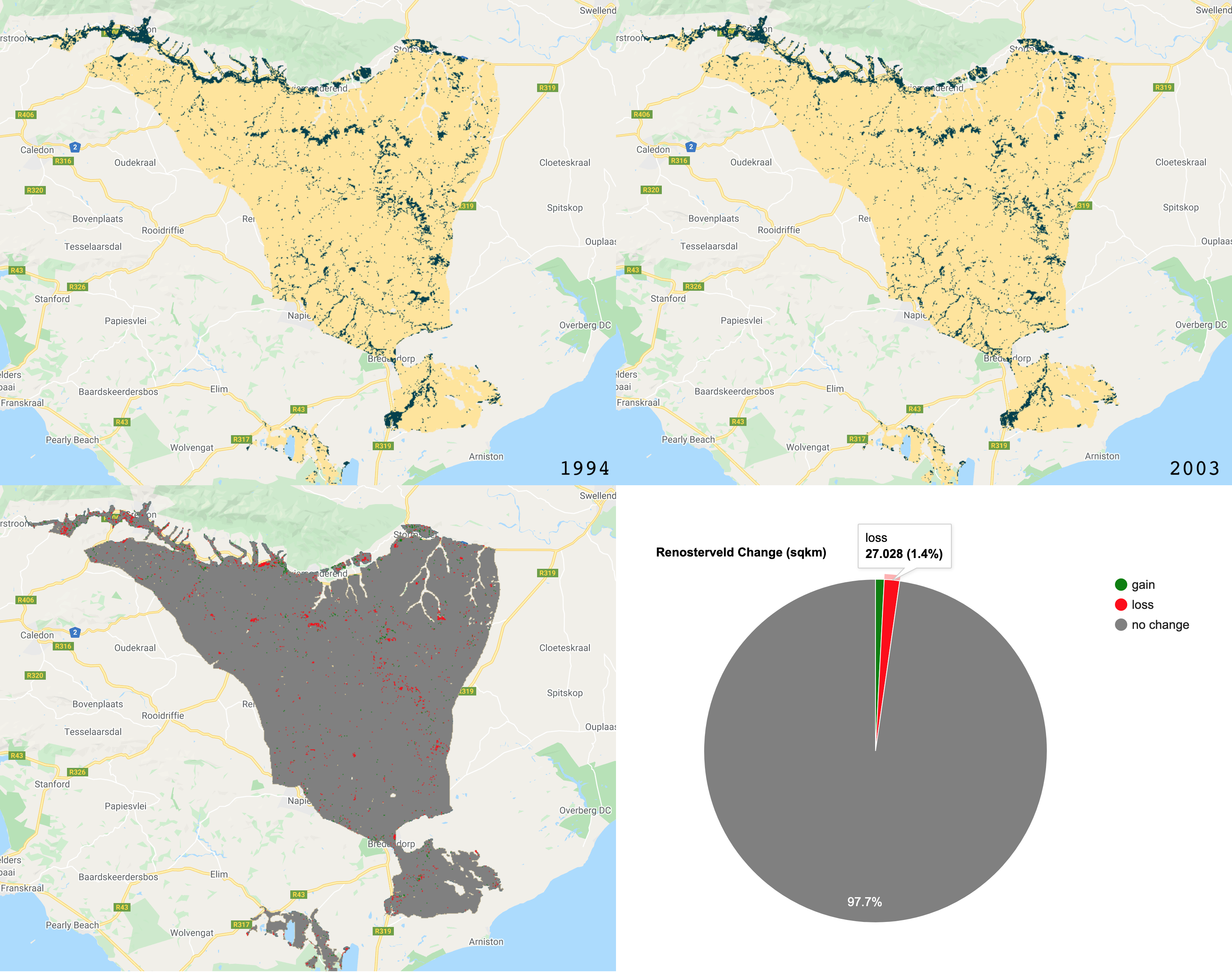
The final step in Part 1, is to visualise the images and calculate a simple binary change from the two images (2015 minus 2005). We will add layers for RGB and NDVI and then add the classified layers.
/////////////////////////////////////////////////////// /// Visualisation ///////////////////////////////////// /////////////////////////////////////////////////////// // Creat a palette for the NDVI layer var palette = palettes.crameri.bamako[10].reverse(); // Add the layers to the map // RGB images Map.addLayer(Image_1994, {bands: ['RED', 'GREEN', 'BLUE'], min:0, max:0.3}, 'image 1994 RGB', false) Map.addLayer(Image_2003, {bands: ['RED', 'GREEN', 'BLUE'], min:0, max:0.3}, 'image 2003 RGB', false) // NDVI layers Map.addLayer(Image_1994, {bands: 'NDVI', min: 0, max: 1, palette: palette}, 'image 1994 NDVI', false) Map.addLayer(Image_2003, {bands: 'NDVI', min: 0, max: 1, palette: palette}, 'image 2003 NDVI', false) // Classifications Map.addLayer(Classification_1994, {min: 0, max: 1, palette: ['FFE599','00404D']}, 'classification 1994', false) Map.addLayer(Classification_2003, {min: 0, max: 1, palette: ['FFE599','00404D']}, 'classification 2003', false) ///////////////////////////// // Simple Binary Change ///// ///////////////////////////// // Subtract the 2003 classification from the 1993 classification var coverChange = testClassification_2003.subtract(testClassification_1994); // Add the layer to the map. Red = loss; Grey = no change; Green = gain Map.addLayer(coverChange,{palette: ['red','grey','green'], min: -1, max: 1},'Renosterveld Cover Change 1994-2003',false); // Let's create a chart of the area of each class var labels =[ 'gain','no change','loss' ]; var areaClass = coverChange.eq([1, 0, -1]).rename(labels); // Calculate the area for each pixel var areaEstimate = areaClass.multiply(ee.Image.pixelArea()).divide(1e6); // Set up the chart var chart = ui.Chart.image.regions({ image: areaEstimate, regions: studyRegion, reducer: ee.Reducer.sum(), scale: 1000, }).setChartType('PieChart').setOptions({ width: 250, height: 350, title: 'Renosterveld Change (sqkm)', // is3D: true, colors: ['green','red','grey'], }); print(chart);
The GEE code includes a section on creating a legend with two classes. The code segment is quite long, so it has been excluded from this page. The output images for the above script are shown below:
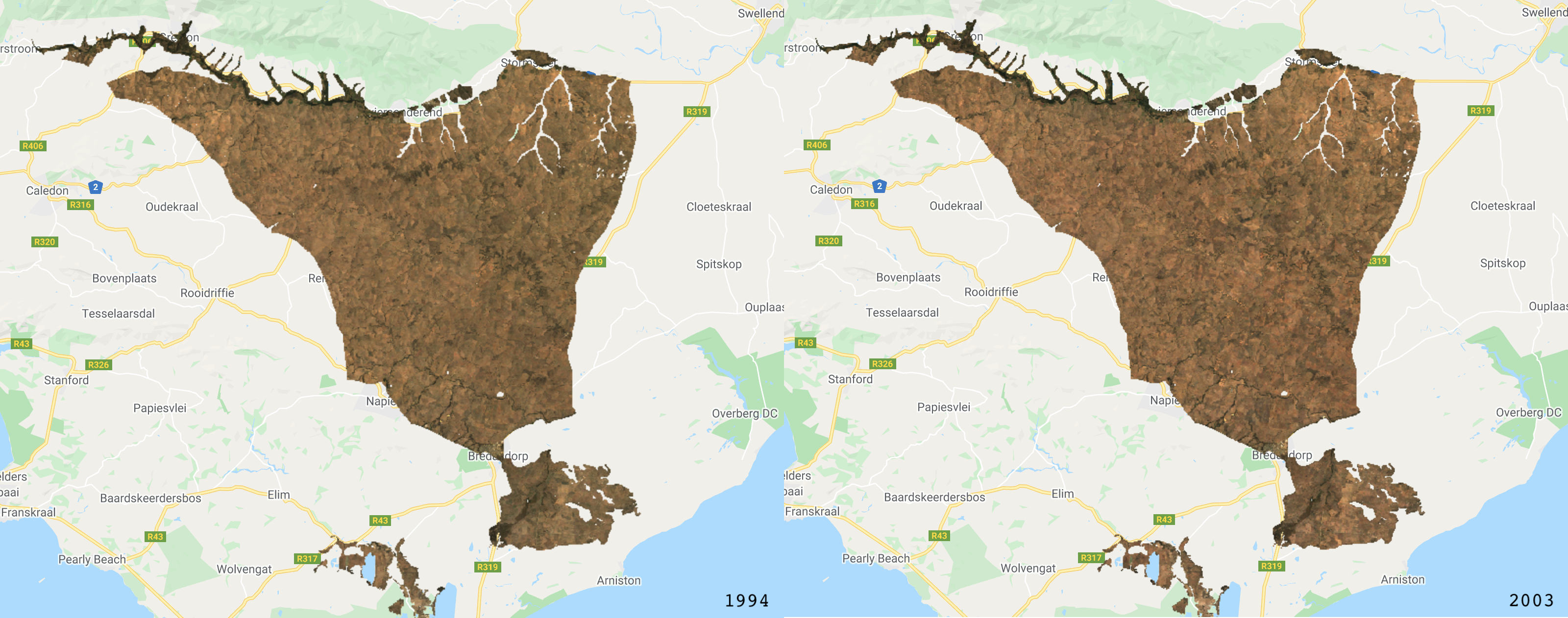
The RGB images.
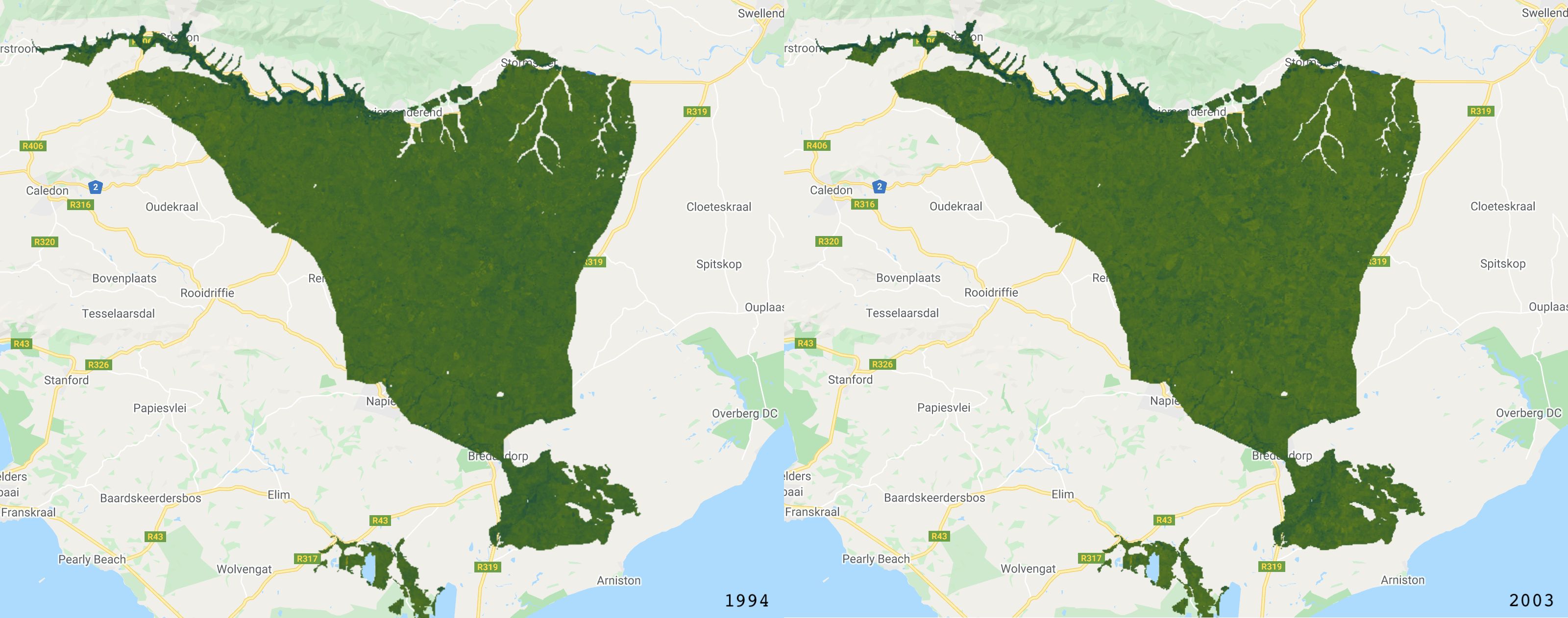
The NDVI images (darker pixels have a higher NDVI value).
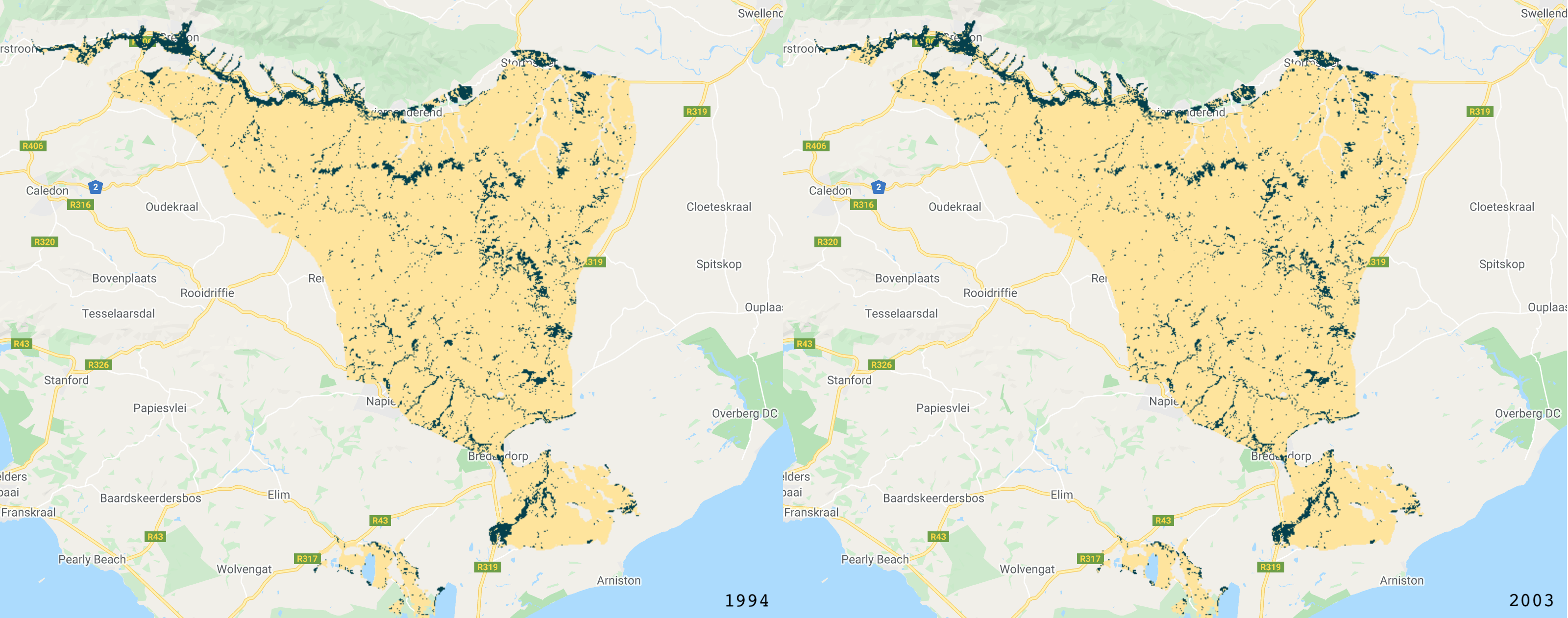
The classified images.
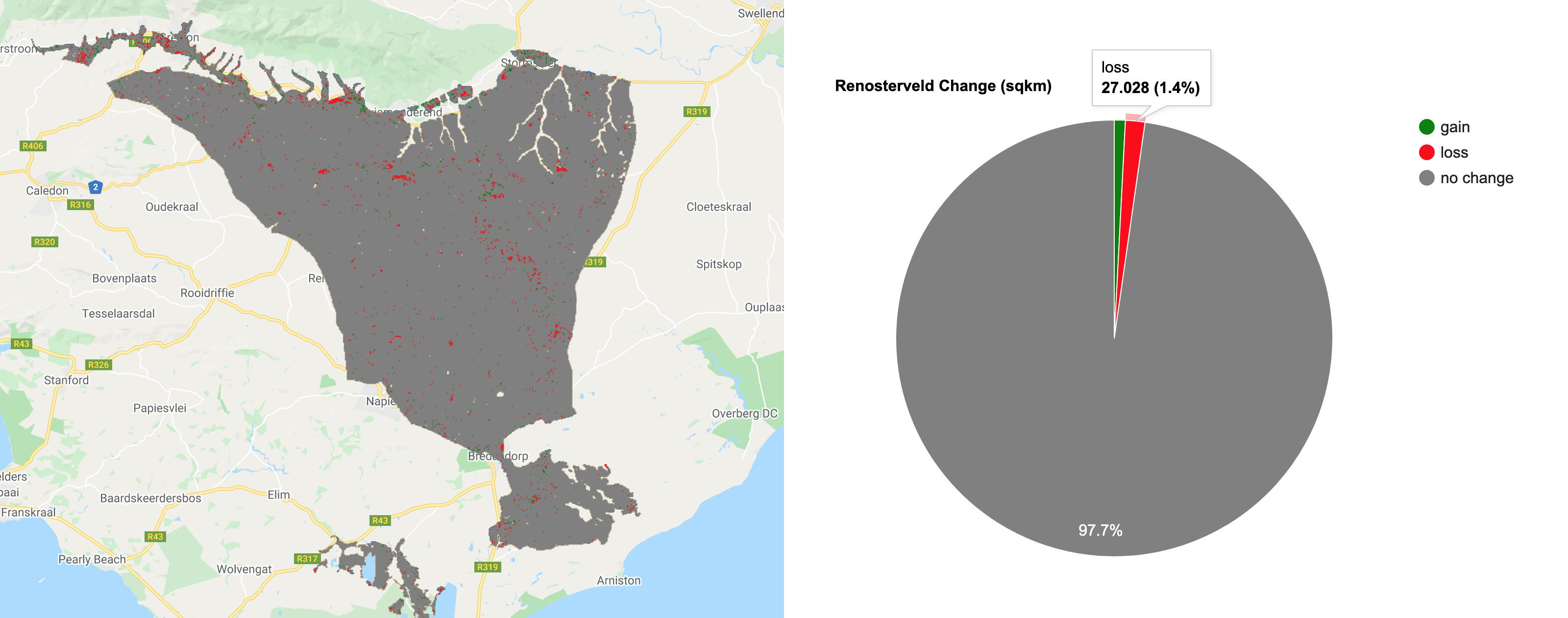
The binary change image, showing losses, gains and no change in forest cover.
Note: this is a very basic approach to area estimation and recent literature suggests that biases due to classification errors may limit this approach. For more information on alternative approaches, read the Arévalo et al. 2020 paper and see https://area2.readthedocs.io/en/latest/overview.html
Part 2: Access the completed practical script here.
The end product for Part 2:
For Part 2, start in a similar way by setting up your map options and loading the additional libraries. This time we will only use the CCDC utilities package.
///////////////////////////////// ///// Set map options /////////// ///////////////////////////////// // Create a polygon/import a featureCollection var renost_all = ee.FeatureCollection('users/jdmwhite/renosterveld_veg_types') var studyRegion = renost_all.filter(ee.Filter.eq('NAME','Central Rens Shale Renosterveld')) // Map.centerObject(studyRegion, 10) ///////////////////////////////// ///// Load extra libraries ////// ///////////////////////////////// // The utilities package for ccdc is the best developed of the ccdc api's var utils = require('users/parevalo_bu/gee-ccdc-tools:ccdcUtilities/api') // the palettes package for map outputs var palettes = require('users/gena/packages:palettes');
Now import your CCDC image ('results') from Part 1 that were exported to your assets. There is a problem now... the CCDC image is stored as an array. This is done because before starting, we do not know the length of each variable calculated by the CCDC algorithm. Some have many segments, some hav few. This means we need to convert it to a 'regular' or 'synthetic' EE image. First create a list of the bands you are interested in, followed by the max. number of segments you are expecting. Lastly, run the buildCcdImage function, which will perform the conversion for you.
/////////////////////////////////////////// ///// Import Data ///////////////////////// /////////////////////////////////////////// // Load the CCDC results back in var results = ee.Image("users/jdmwhite/renost_ccdc_raw_1993_2003_2_v1") print(results) /////////////////////////////////////////// ///// Process ///////////////////////////// /////////////////////////////////////////// // Spectral band names. This list of all the bands we are interested in var BANDS = ['BLUE', 'GREEN', 'RED', 'NIR', 'SWIR1', 'SWIR2', 'NDVI'] // Names of the temporal segments and the number. There are not likely to be more than // 4 segments for each pixel var SEGS = ["S1", "S2", "S3", "S4"] // Obtain CCDC results in 'regular' ee.Image format var ccdImage = utils.CCDC.buildCcdImage(results, SEGS.length, BANDS) print('ccdImage:',ccdImage);
We now run the filterMag function, which extracts three bands from the 'synthetic' image. This includes the time of the biggest break (tBreak), the total number of breaks (numTbreak) and the magnitude of the biggest break (MAG). Select a band to use (as different bands may produce different segmentation) and the number of segments to extract and ensure that your dates are correctly formatted.
// Convert the date to a format required var changeStart = '1993-01-01' var changeEnd = '2002-01-01' var startParams = {inputFormat: 3, inputDate: changeStart, outputFormat: 2} // 3 is for string var endParams = {inputFormat: 3, inputDate: changeEnd, outputFormat: 2} // 2 is for milliseconds since 1970 var formattedStart = utils.Dates.convertDate(startParams).aside(print) var formattedEnd = utils.Dates.convertDate(endParams).aside(print) // Run the filterMag function from the utils package // This extracts information on the time of the biggest break (tBreak) // the magnitude of the biggest break (MAG) and the total number of breaks (numTbreak) // for a specified band (in this case NDVI) var filteredChanges = utils.CCDC.filterMag(ccdImage, formattedStart, formattedEnd, 'NDVI', SEGS) print('filterChanges:',filteredChanges);
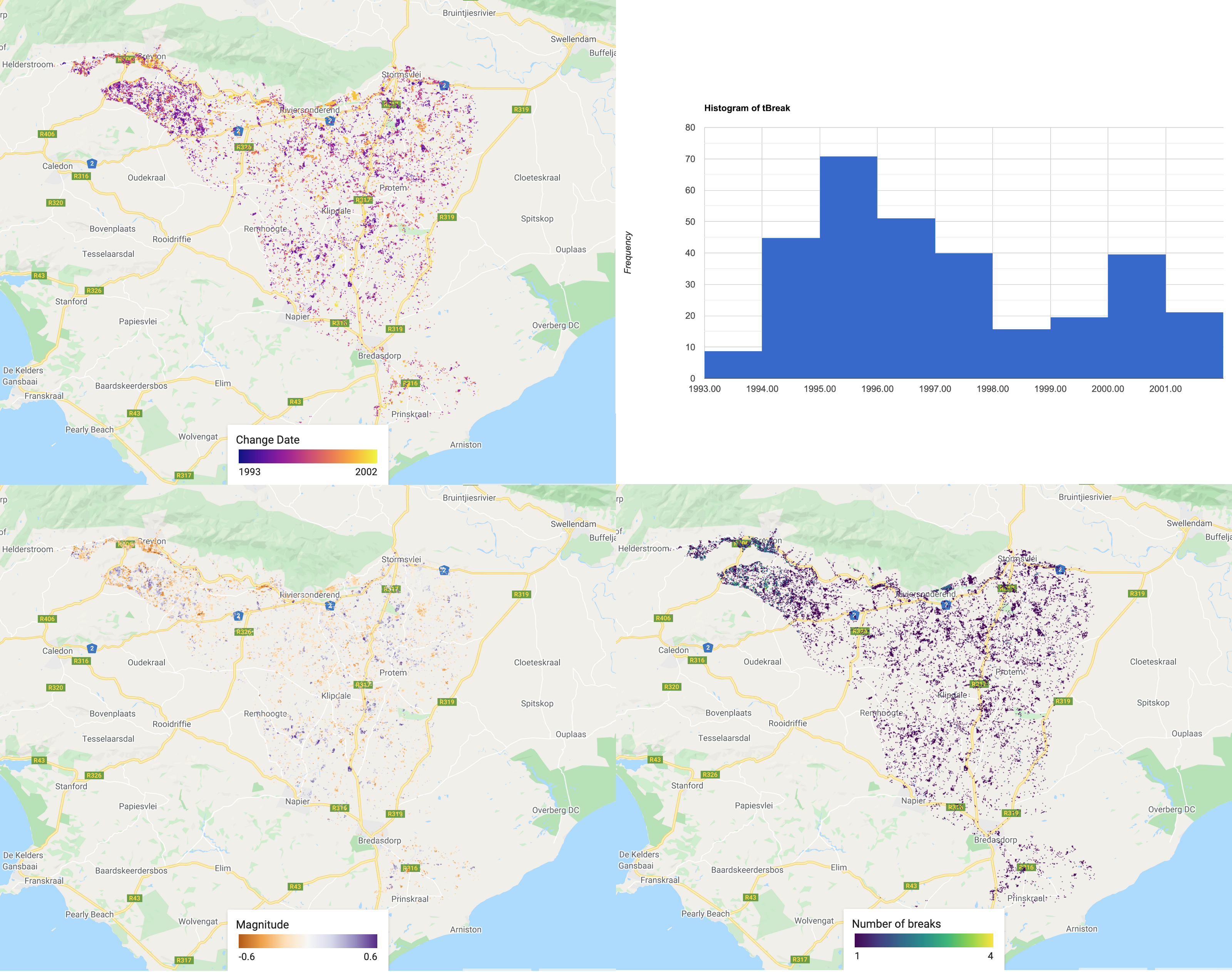
Now visualise the different images and run a quick histogram to see the distribution of the major change dates. The full GEE code, shows how to create legends and how to customise the basemap. These are long code segments, so they have been excluded from this page.
/////////////////////////////////////////// ///// Visualisation /////////////////////// /////////////////////////////////////////// // A chosen palette var change_date_palette = palettes.matplotlib.plasma[7]; var mag_palette = palettes.colorbrewer.PiYG[7]; var num_breaks_palette = palettes.crameri.buda[10]; // Convert millis to fractional year // divide by no. of millis in one year; add on 1970 as baseline var tBreak = filteredChanges.select('tBreak').divide(31556952000).add(1970) // The time of break Map.addLayer(tBreak, {min: 1993, max: 2002, palette: change_date_palette}, 'Change date'); // The magnitude of break Map.addLayer(filteredChanges.select('MAG'), {min: -0.6, max: 0.6, palette: mag_palette}, 'Magnitude'); // The number of breaks Map.addLayer(filteredChanges.select('numTbreak'), {min: 1, max: 4, palette: num_breaks_palette}, 'Number of breaks'); // Histogram of date of change // Make sure you have your original study region defined var hist = ui.Chart.image.histogram({ image:tBreak, region:studyRegion, minBucketWidth: 1, scale: 1000, }) print(hist); // Add in legend for aid in visualisation
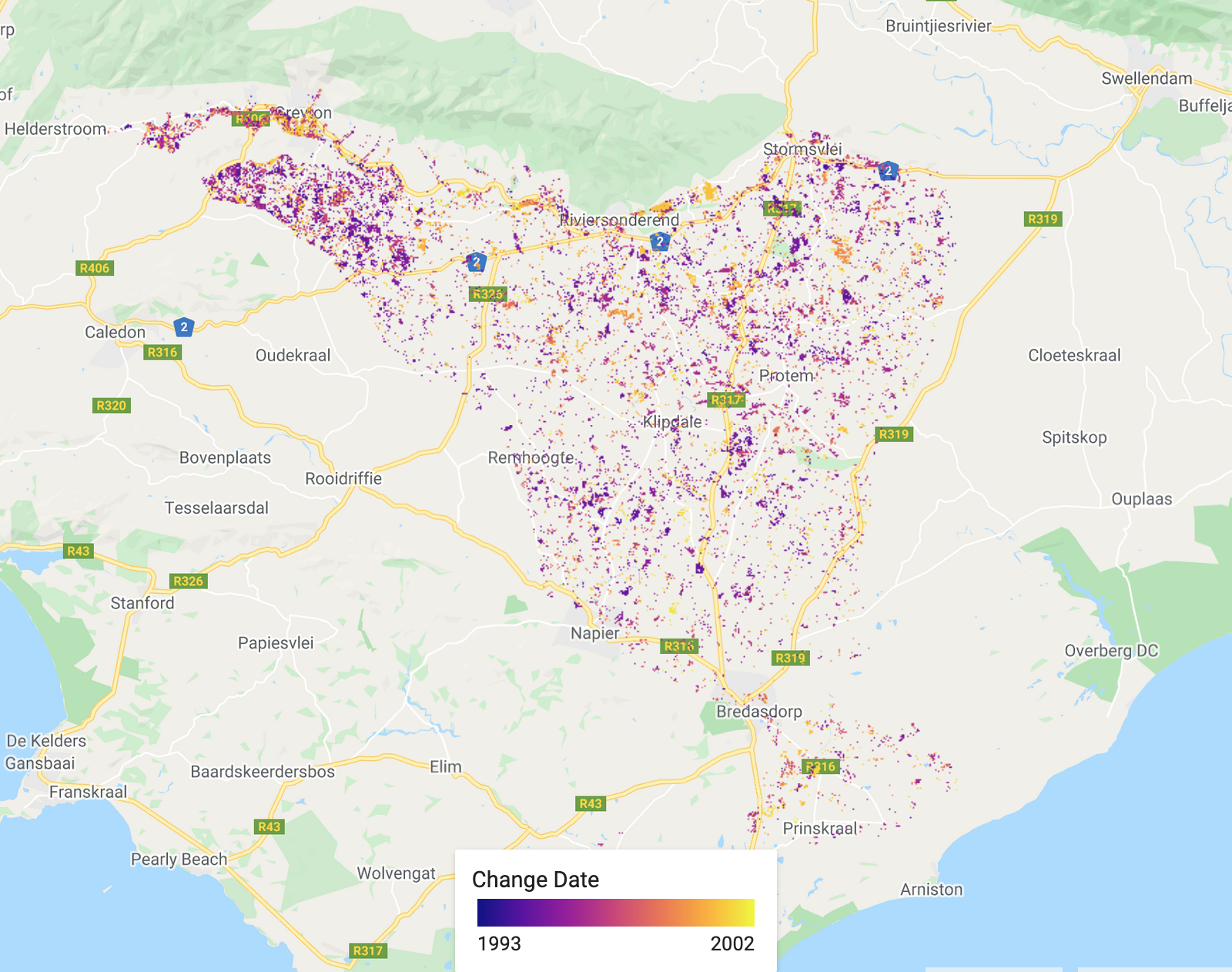
The date of the biggest change.
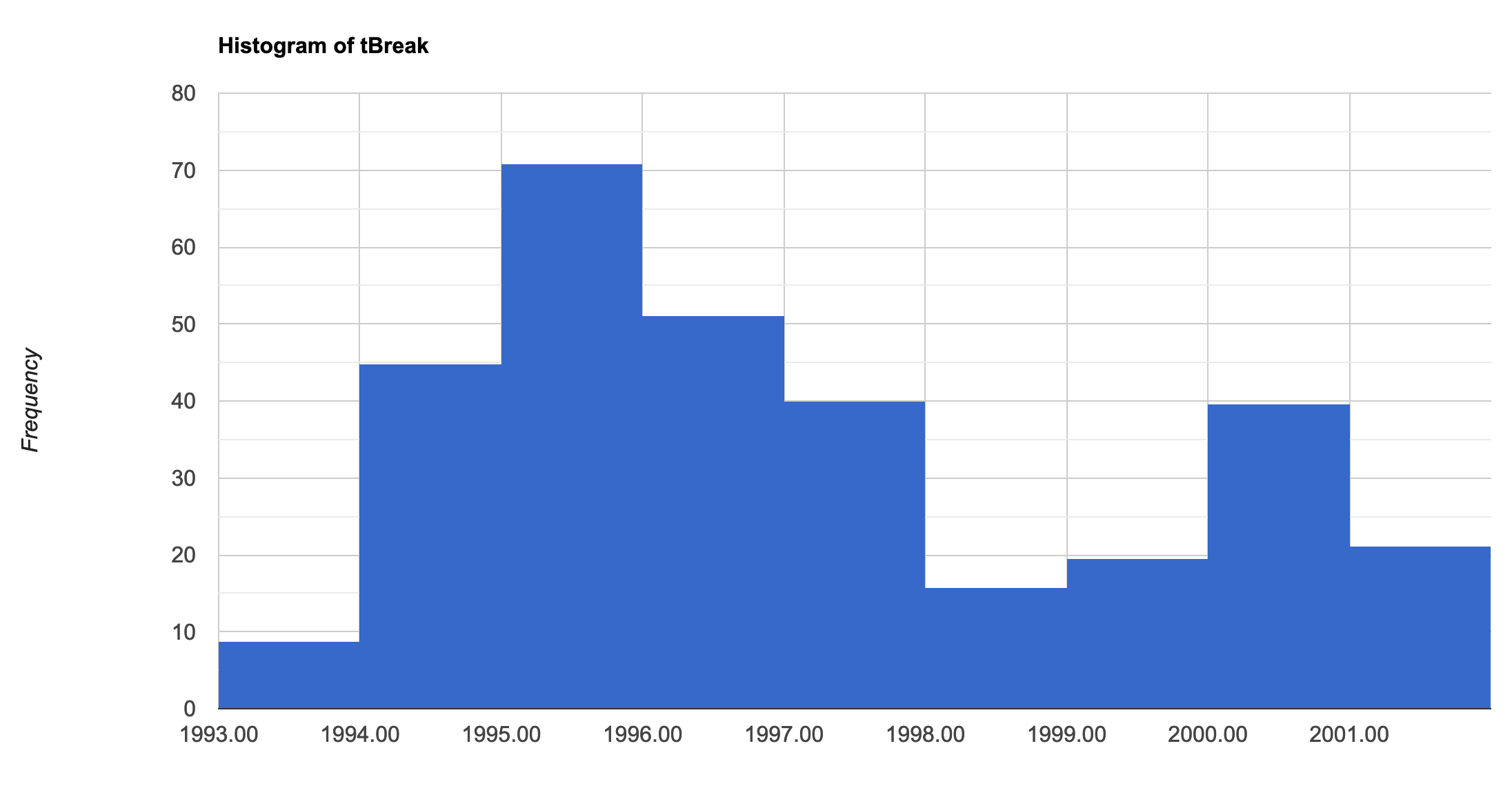
Histogram showing the distribution of the date of biggest change.
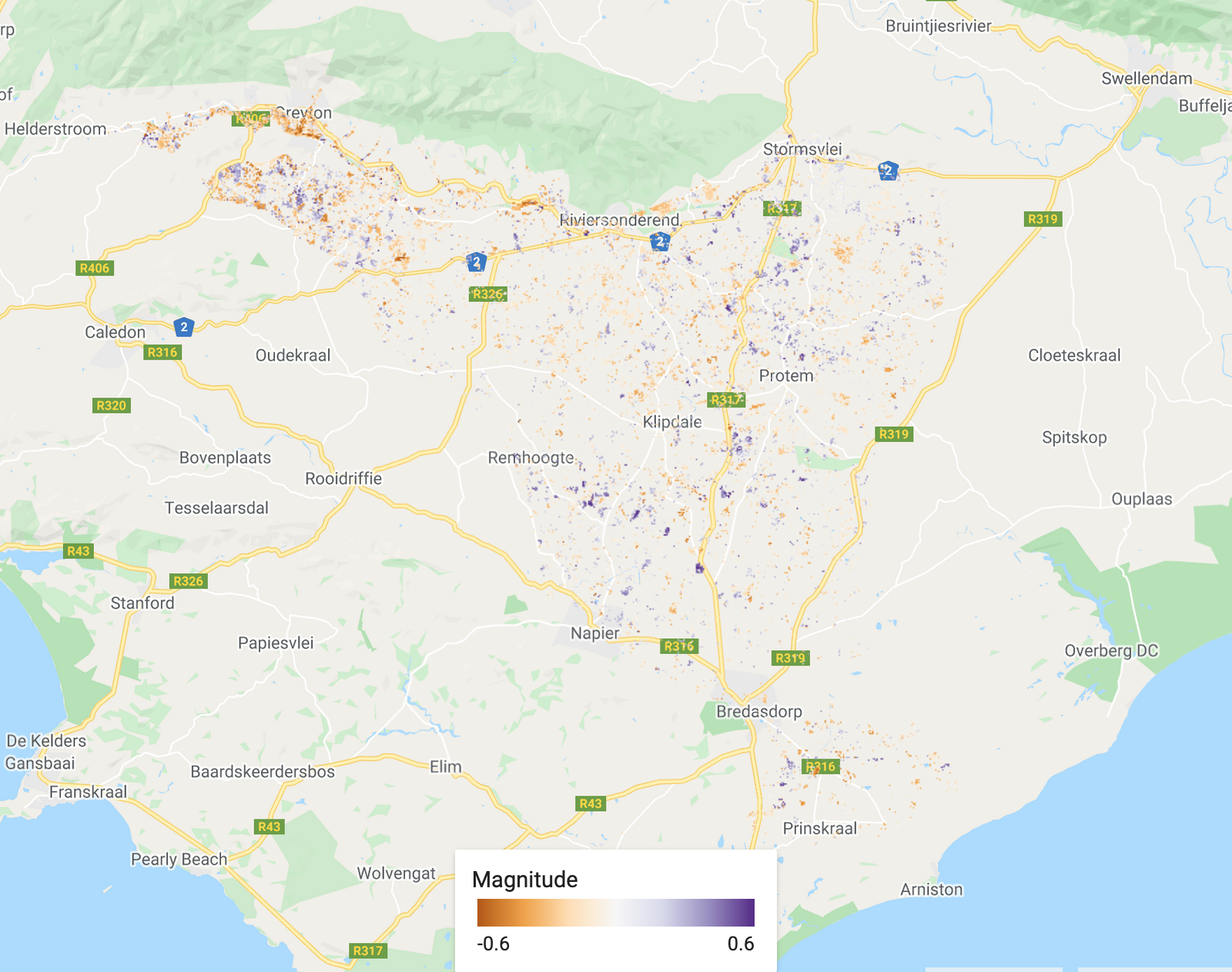
The magnitude of the biggest change. Purple shows a decrease in the chosen band (SWIR1 in this case) and orange shows an increase.
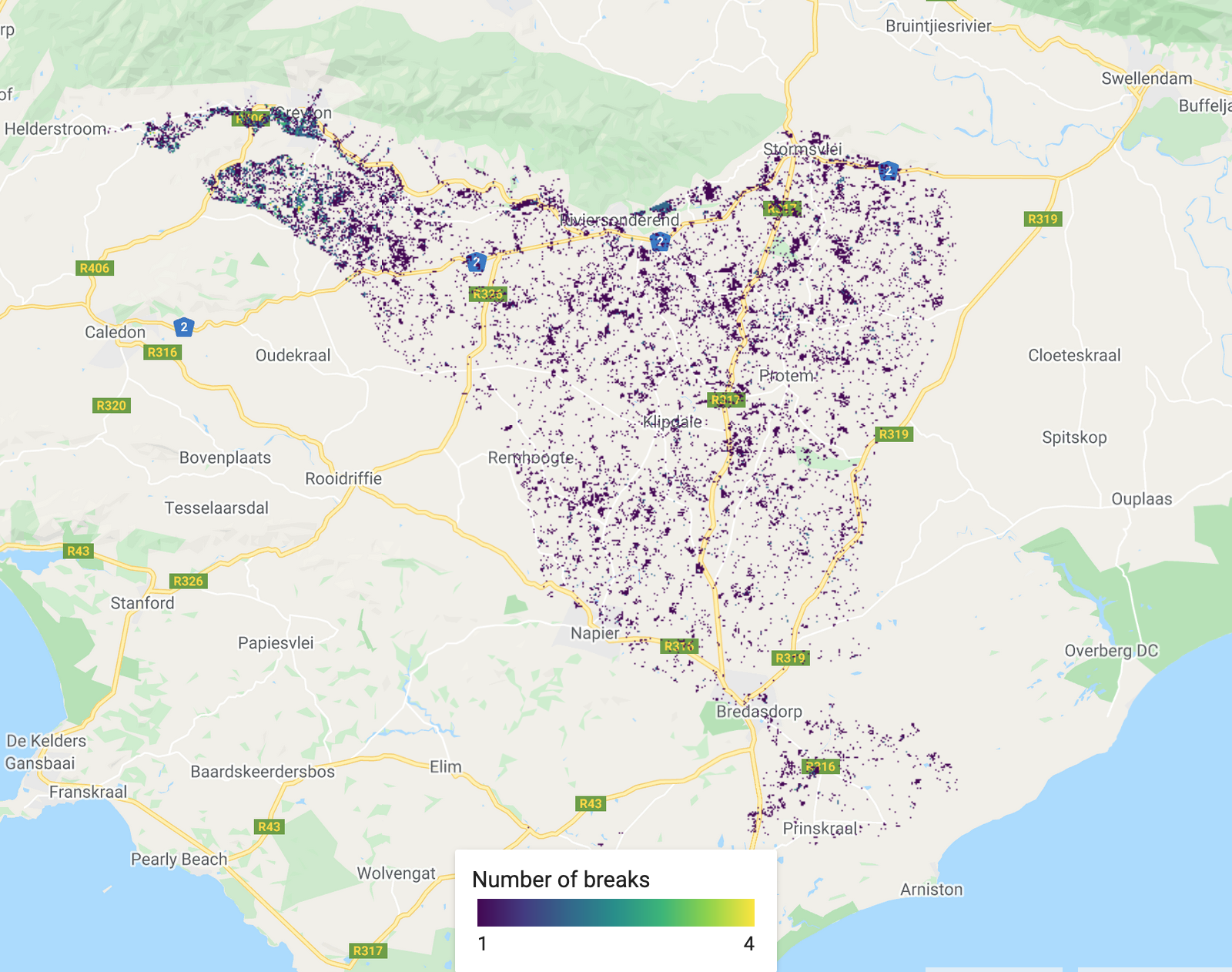
The total number of changes (segments) recorded. Dark colours show less changes.
There is no assignment for this practical